Solving a long running CPU issue
Introduction
Ryot had an issue that took me around 10 months to debug. Here are some graphs to illustrate the issue:
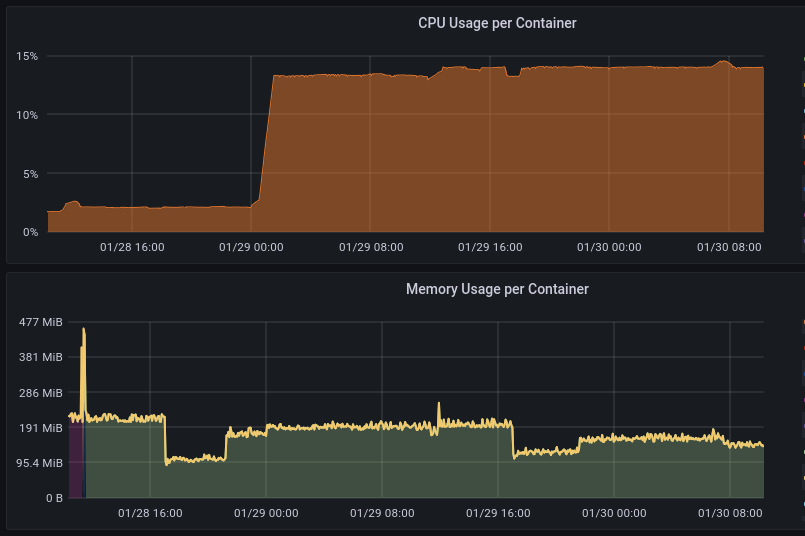
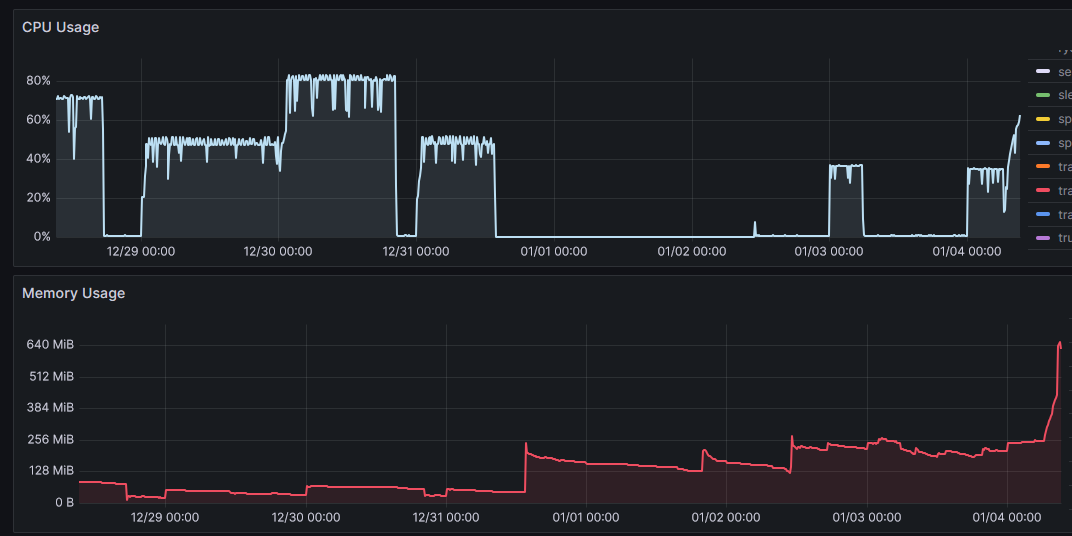
At midnight everyday, the CPU usage would increase. This in itself was expected since the server runs a cron job at that time. However, the CPU usage stack up over time and never come down to normal. I was not able find a suitable way to reproduce the issue on my local machine.
Debugging
I was pretty sure from day one that this was not a memory leak issue since the backend is
written in 100% safe Rust. The first
breakthrough came when
I stopped shipping musl versions and switched to glibc with the Docker image.
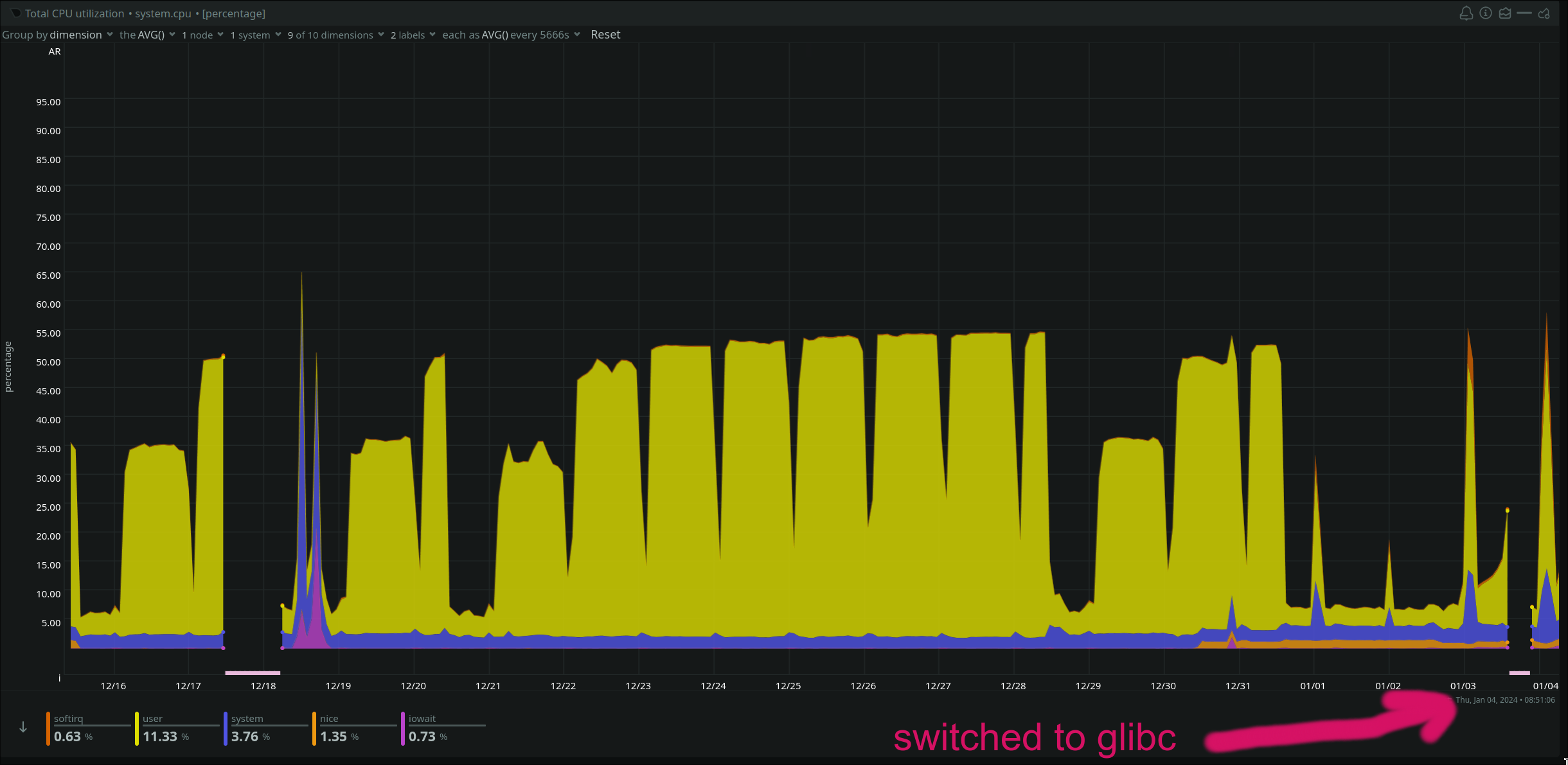
Next, I introduced environment variables that allowed me to selected which cron jobs I wanted to run. This allowed me to isolate the issue to a single cron job.
In the end the problem was pretty simple. Here is a comment I wrote explaining the situation:
Yep, you’re right. I believe it is not actual metadata update that is causing the problem but the associated person data being updated that is the problem. Shows have a lot of people associated with them, the problem compounds with more of them being monitored.
Essentially, every night the job updated the metadata for the monitored media. I had around 50 of them. This in itself is not very expensive since it is one API call and 3 DB calls. However, each media itself is associated with ~60 people.
As a result, it ended up kicking off 3000 jobs every night to update people details. This was incredibly wasteful since the people details almost never change.
Solution
I went with a lazy evaluation solution. Now only the minimum possible details of a person are saved to the database when a media is updated. The data only gets updated when the user actually views the person’s details. Updating a media no longer kicks a job to update the people associated with it.
Here is a graph of the CPU usage after the fix:

The fix was deployed 5 days ago, and as you can see, the CPU usage has stayed stable since then.